

こんにちは。AIで勘違いして何でも作ってみる部です。
「ChatGPTってなんでこんなに賢いの?」「どうやって学習してるの?」そんな疑問を持ったことはありませんか? 毎日のようにChatGPTを使っていると、その驚くべき能力の裏側にある仕組みが気になってきますよね。
定期的に「さらに優秀なGPTが登場!」というニュースが流れてきて、「え?どう学習してるの?」「具体的に何が変わったの?」と思うことも多いのではないでしょうか。 優秀になった結果は分かっても、そもそもどういう仕組みで、何が変わったのかってイメージできる人って意外と少ないかもしれません。
でも気になりませんか?「優秀!」なのはわかったけど「何がどう変わったの?」「パソコンの画面だけでなく、リアルでは何が変わってるの?」とかとか
今回は、ChatGPTがどのような学習元から知識を獲得し、どんな学習方法で精度を向上させているのか、技術的な部分も含めて分かりやすく解説していきます。 学習機能の削除方法や、AIの「考える」能力についても詳しくお話ししていきたいと思います。
もしよかったら最後まで読んでみてください。
AI活用・DXを推進する法人研修

企業様の課題や人材育成計画にあわせた法人研修・DX推進プログラムを企画・提供させていただいています。基礎から応用・開発まで気軽にお問合せください。
ChatGPTの基本概念と学習の全体像
GPTとは何か?基本から理解しよう
GPT(Generative Pre-trained Transformer)は、OpenAIが開発した大規模言語モデルの名称です。 この名前には重要な意味が込められており、特に「Pre-trained(事前学習済み)」という部分が重要なポイントになります。
「事前学習済み」というのは、私たちが質問する前から、既に膨大な知識を身につけた状態で会話を始めることができることを意味しています。 これは従来の検索エンジンとは根本的に異なる特徴で、検索エンジンがキーワードマッチングで情報を探してくるのに対し、ChatGPTは内容を理解した上で応答を生成できるのです。

ソフトバンクの孫正義さんも何度かこの話をされており、AIが単なる情報検索ツールから「理解するAI」へと進化していることを強調されています。 この進化は、私たちの働き方や学び方に革命的な変化をもたらしつつあります。
ChatGPTの学習段階を表で整理
| 学習段階 | 目的 | 具体的な内容 | 期間・規模 |
|---|---|---|---|
| 事前学習 | 基礎的な言語理解力の獲得 | インターネット上の大量テキストデータを学習 | 数ヶ月〜1年 |
| ファインチューニング | 特定用途への特化 | 専門分野のデータで追加学習 | 数週間〜数ヶ月 |
| RLHF | 人間の価値観に合わせた調整 | 人間の評価をもとに応答品質を向上 | 継続的 |
■事前学習の段階
ChatGPTは私たちが本をたくさん読んで語彙力を増やしていくのと似たプロセスを経ています。 ただし、その規模は人間の比ではなく、インターネット上の膨大なテキストデータを処理して、言語の基本的な理解力を身につけていきます。
■ファインチューニングの段階
特定の用途に合わせて追加の学習を行います。 例えば、カスタマーサポート用のChatGPTなら、問い合わせ対応の専門知識を重点的に学習するといった具合です。
■最後の人間のフィードバックによる強化学習(RLHF)の段階
人間が「良い回答」「悪い回答」と評価したデータをもとに、より自然で有用な応答ができるよう調整されます。 この段階が、ChatGPTを単なる情報処理システムから、人間の価値観に沿ったAIアシスタントへと変貌させる重要なプロセスなのです。
ChatGPTの学習元データと保存場所

学習データの種類と詳細な特徴
ChatGPTの学習に使用されるデータソースは非常に多岐にわたり、その種類と質が最終的な性能を大きく左右します。
ウェブページとオンラインコンテンツ インターネット上の一般的なウェブページ、ブログ、フォーラム投稿などが主要な学習源となっています。 これらのデータからは、日常会話やカジュアルな表現、最新のトレンドなどを学習することができます。 ただし、情報の品質にばらつきがあるため、適切なフィルタリングが重要になります。
学術文献と専門書籍 学術論文、教科書、専門書といった高品質な文献も重要な学習源です。 これらからは、正確で体系化された専門知識を獲得することができ、ChatGPTの回答の正確性と信頼性を支える基盤となっています。 法律文書や科学論文のデータベースも含まれており、専門分野での応答能力向上に寄与しています。
構造化された公開データセット WikipediaやCommon Crawlなどの構造化された公開データセットは、比較的信頼性の高い情報源として重宝されています。 これらのデータセットは、情報の正確性がある程度担保されており、事実に基づいた回答を生成するための重要な基盤となっています。
ニュース記事とソーシャルメディア 報道記事やソーシャルメディアの投稿からは、時事情報や社会のトレンドを学習します。 ただし、これらの情報は時間の経過とともに陳腐化する可能性があるため、情報の鮮度管理が課題となっています。
個人情報や機密情報、著作権で保護されたコンテンツの取り扱いには、法的・倫理的な配慮がなされているとされていますが、この点については継続的な議論が必要な領域でもあります。
ユーザーデータの保存場所と期間の詳細
私たちがChatGPTとやり取りしたデータがどこに、どのくらいの期間保存されるのかは、プライバシーの観点から非常に重要な情報です。
データの保存場所 ChatGPTに入力したプロンプトや質問、会話内容は、OpenAIが管理するサーバーに保存されます。 これらのサーバーは主に米国のデータセンターに設置されており、現時点ではヨーロッパやその他の国には保存されていないようです。
保存される情報には、テキスト入力だけでなく、位置情報やデバイス情報、アカウント情報なども含まれる場合があります。 これらの情報は、サービスの改善や不正利用の監視などの目的で活用されています。
保存期間と削除ポリシー 通常の設定では、会話データは基本的に無期限で保存され、モデルの改善や学習に活用される可能性があります。 ただし、「学習に利用しない」オプションを選択することも可能で、この場合でも不正利用の監視などの目的で30日間はデータが保持され、その後完全に削除されるとされています。
Temporary Chat FAQ
Updated over 3 weeks ago
With Temporary Chat, you can have a conversation with a blank slate. ChatGPT won’t be aware of previous conversations or access memories. It will still follow your custom instructions if they’re enabled.
Will my Temporary Chats appear in my history?
Temporary Chats won’t appear in your history, and ChatGPT won’t remember anything you talk about. For safety purposes we may still keep a copy for up to 30 days.
Will Temporary Chats be used for training?
Temporary Chats won’t be used to improve our models.
How do I start a Temporary Chat?To start a Temporary Chat, open a new chat and click the pill-shaped “Temporary” button in the top-right corner of the page.
Will GPT builders be able to see what I say with Temporary Chats?
You can have temporary chats with GPTs. If the GPT has actions, data sent to third parties through those actions is subject to the recipient’s privacy policy. That means the recipient may keep that data for longer than 30 days and may use it for other purposes.
Enterprise customers – are Temporary Chats available in the Compliance API?
Yes, Temporary Chats are available by the accessing the Compliance API. Temporary chats will be available in the Compliance API for 30 days regardless if a custom retention period is defined.
出典:OpenAI 公式FAQ https://help.openai.com/en/articles/8914046-temporary-chat-faq
AI活用・DXを推進する法人研修
企業様の課題や人材育成計画にあわせた法人研修・DX推進プログラムを企画・提供させていただいています。基礎から応用・開発まで気軽にお問合せください。
パラメータとニューラルネットワークの関係
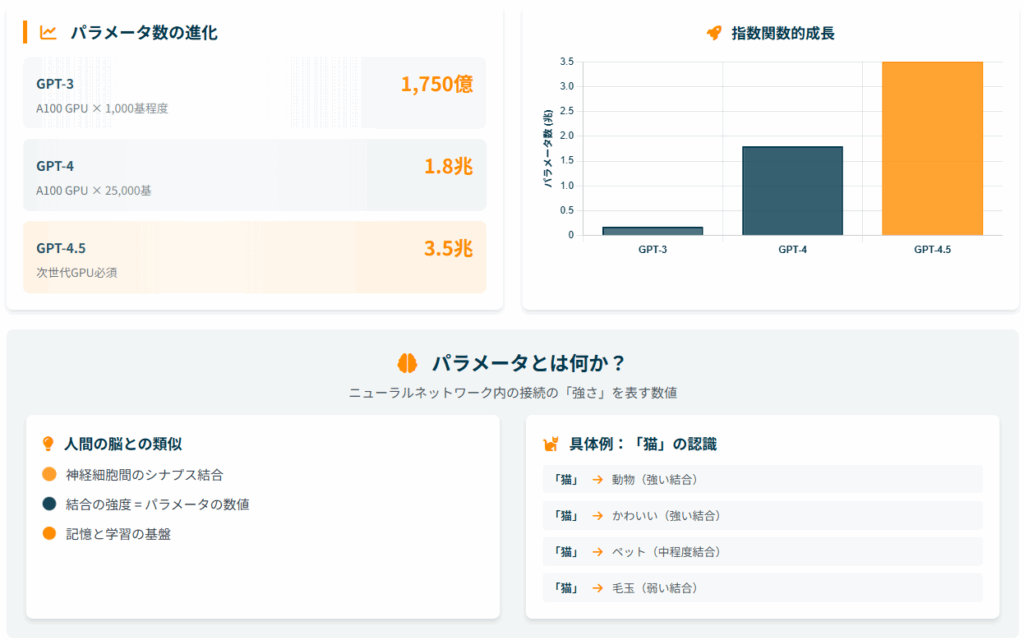
パラメータ数の進化を数値で見る
| モデル | パラメータ数 | 主な改善点 | 計算能力要件 |
|---|---|---|---|
| GPT-3 | 1,750億 | 基本的な対話能力 | A100 GPU × 1,000基程度 |
| GPT-4 | 1.8兆 | 推論能力向上 | A100 GPU × 25,000基 |
| GPT-4.5 | 3.5兆 | 効率性と精度の両立 | 次世代GPU必須 |
ChatGPTの進化を語る上で最も重要な指標の一つが、パラメータ数の増加です。 GPT-3の1,750億個から始まり、GPT-4では1.8兆個、そして最新のGPT-4.5では3.5兆個まで増加しているとされています。
この数字の増加は、単純に「より大きくなった」ということ以上の意味を持っています。 パラメータ数の増加は、AIが扱える情報の複雑さと精度の向上に直結しており、これがChatGPTの驚くべき能力向上の背景にあるのです。
パラメータの役割と詳細なメカニズム
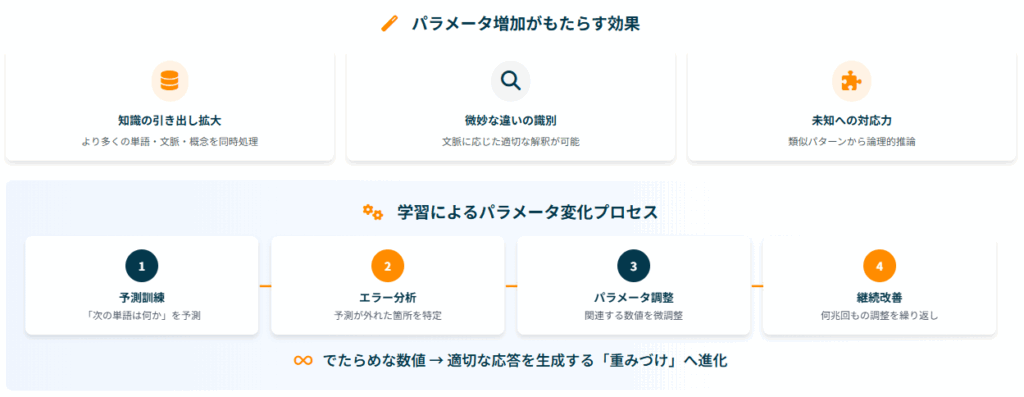
パラメータとは何か 「パラメータ」とは、ニューラルネットワーク内の各ニューロン間の接続の「強さ」を数値で表したものです。 人間の脳で例えると、神経細胞間のシナプス結合の強度に相当します。
例えば、ChatGPTが「猫」という単語を見たとき、「動物」「かわいい」「ペット」「毛玉」「鳴き声」といった関連する概念との結びつきの強さが、それぞれ異なるパラメータの数値として保存されています。 これらの数値の組み合わせによって、ChatGPTは文脈に応じた適切な応答を生成できるようになっています。
パラメータ増加がもたらす具体的効果
1. 知識の引き出しの拡大 パラメータはAIの「記憶装置」のようなもので、数が増えると、より多くの単語・文脈・概念を同時に扱えるようになります。 小説のストーリー展開を予測する際、登場人物の関係性、過去のエピソード、文学的技法、ジャンルの特徴などを細かく記憶し、それらを総合して判断できるようになります。
2. 微妙な違いの識別能力 類似した単語や曖昧な表現でも、文脈に応じた適切な解釈が可能になります。 「Bank(銀行・金融機関)」と「bank(土手・川岸)」を文脈から正確に区別できるような能力や、皮肉や比喩表現の理解も向上します。
3. 未知の状況への対応力強化 学習データにない質問にも、類似パターンから論理的に推論できるようになります。 初めて見る数学問題を、既知の公式の組み合わせで解くような応用力や、異なる分野の知識を組み合わせた創造的な回答が可能になります。
学習によるパラメータの変化プロセス
基本的な学習メカニズム 学習の過程で、ChatGPTは大量のテキストデータを読み込み、「次にどの単語が来るか」を予測する訓練を繰り返します。 予測が外れると、どこで間違えたのかを分析し、関連するパラメータの数値を微調整していきます。
このプロセスは、人間が楽器の練習をするときに、間違えた箇所を重点的に練習して上達していくプロセスによく似ています。 最初はでたらめだった数値が、何兆回もの調整を経て、適切な応答を生成できる「重みづけ」に変化していくのです。
フィードバックループによる継続的改善 ChatGPTの学習は、一度で終わりではありません。 ユーザーからのフィードバックや専門家からの評価を収集し、その情報をもとにパラメータを再調整する「フィードバックループ」が継続的に回されています。
このフィードバックループは、フィードバックの収集、データのキュレーションと品質管理、再トレーニング、テストと評価、再デプロイとモニタリングという段階を経て実施されます。 これにより、時代や環境の変化に柔軟に適応し、継続的に精度と信頼性を高めていく仕組みが構築されています。
AI活用・DXを推進する法人研修
企業様の課題や人材育成計画にあわせた法人研修・DX推進プログラムを企画・提供させていただいています。基礎から応用・開発まで気軽にお問合せください。
GPUとChatGPT学習の関係性
GPU活用の技術的背景と必要性
ChatGPTのような大規模言語モデルの学習には、膨大な計算処理が必要です。 ここで重要な役割を果たすのがGPU(Graphics Processing Unit)で、その理由は計算の性質にあります。
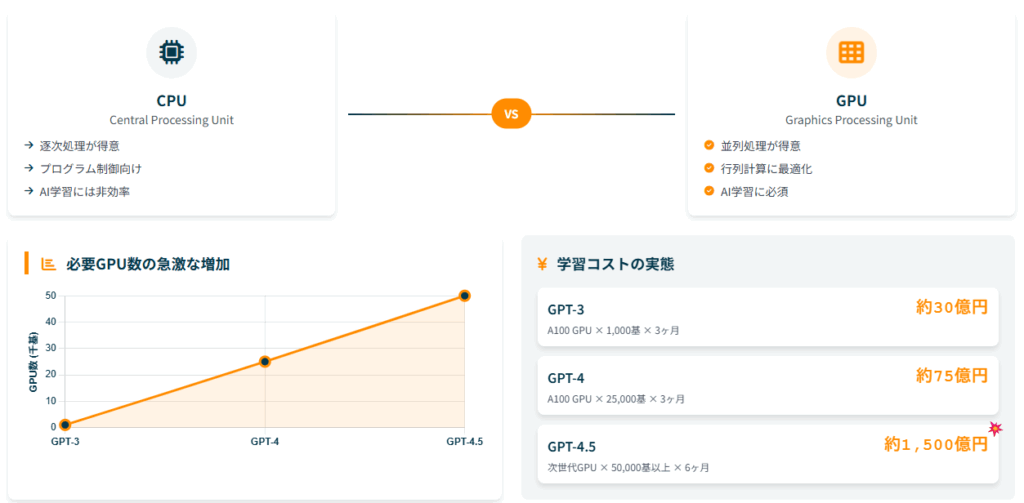
GPUの特性とAI学習への適用 もともとGPUは、3Dゲームなどの画像処理のために開発されたハードウェアでした。 3D画像を滑らかに表示するためには、多数の点データに対して同時に複雑な計算を行う必要があり、このための並列計算能力がGPUの最大の特徴です。
実は、この画像処理用の計算と、ニューラルネットワークの重みづけ(パラメータ)を探すための学習計算は、とても似た性質を持っています。 どちらも大量の数値データに対して同じような計算を並列で実行する必要があるため、ほぼ同じ計算式で重みづけの最適値を解くことができるのです。
CPUは逐次処理が得意でプログラム制御に向いていますが、GPUは並列処理が得意で行列計算に最適化されています。 AI学習では大量の行列演算が必要になるため、GPUの方が圧倒的に効率的なのです。
パラメータ数とGPU必要数の具体的関係
コストと規模の実態 パラメータ数を増やすこと自体は、GPUを増やすことで直接実現されるわけではありません。 より正確に言うと、大きなモデル(多くのパラメータを持つモデル)を学習させるためには、より多くのGPUが必要になるという関係性があります。
GPT-3(1,750億パラメータ)では約1,000基のNVIDIA A100 GPUが2-3ヶ月間必要とされ、推定コストは約30億円でした。 GPT-4(1.8兆パラメータ)の学習には25,000基のNVIDIA A100 GPUを90-100日間稼働させる必要があったとされ、1基あたり約300万円とすると、ハードウェア単体で75億円規模の投資が必要になります。
最新のGPT-4.5(3.5兆パラメータ)では50,000基以上のGPUが6ヶ月以上必要とされ、約1,500億円という莫大なコストがかかるとされています。 このように、パラメータ数の増加は指数関数的なコスト増加を伴うのです。
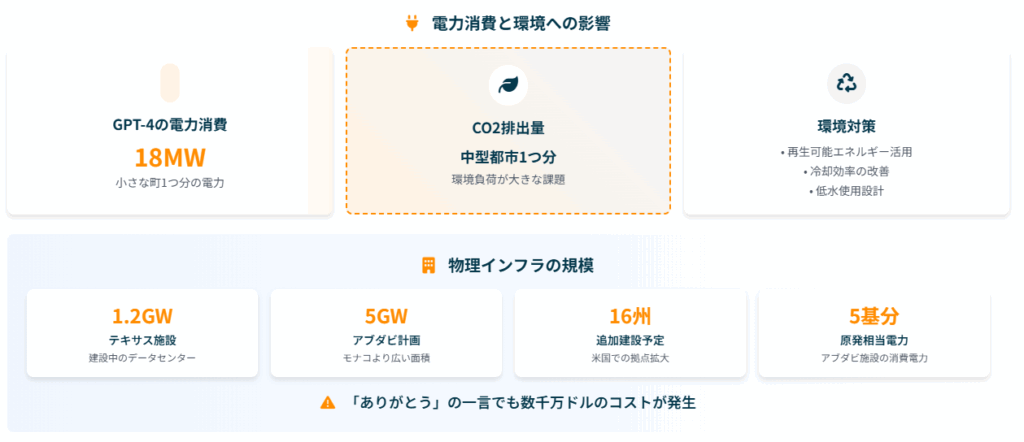
電力消費と環境負荷 GPUの大量使用は、電力消費の増大も意味します。 GPT-4では18MWの電力を消費するとされており、これは小さな町一つ分の電力消費量に相当します。
以前、ChatGPTに「ありがとう」と礼儀正しく伝えるだけでも、OpenAIのCEOサム・アルトマン氏が「数千万ドル」のコストを生み出していると発表して話題になったことがありますが、これはこうした膨大なインフラコストが背景にあるためです。
計算効率と推論能力の向上メカニズム
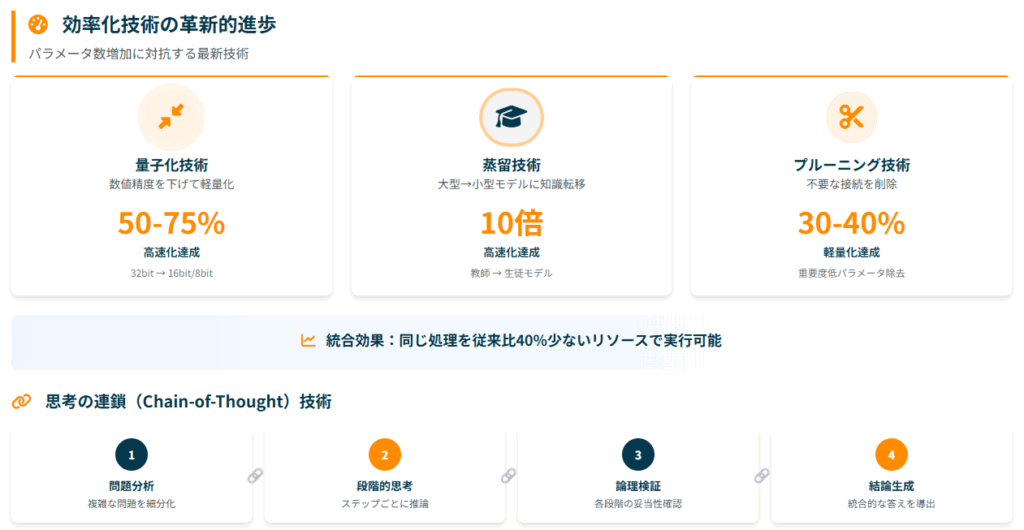
効率化技術の詳細な進歩
パラメータ数が増加すると、計算コストも指数関数的に増加してしまいます。 そこで重要になるのが「計算効率の改善」で、様々な技術が開発されています。
量子化技術 量子化により、モデルの数値精度を下げることでサイズを削減し、50-75%の高速化を実現しています。 32ビットの浮動小数点数を16ビットや8ビットに変換することで、メモリ使用量と計算時間を大幅に削減できます。
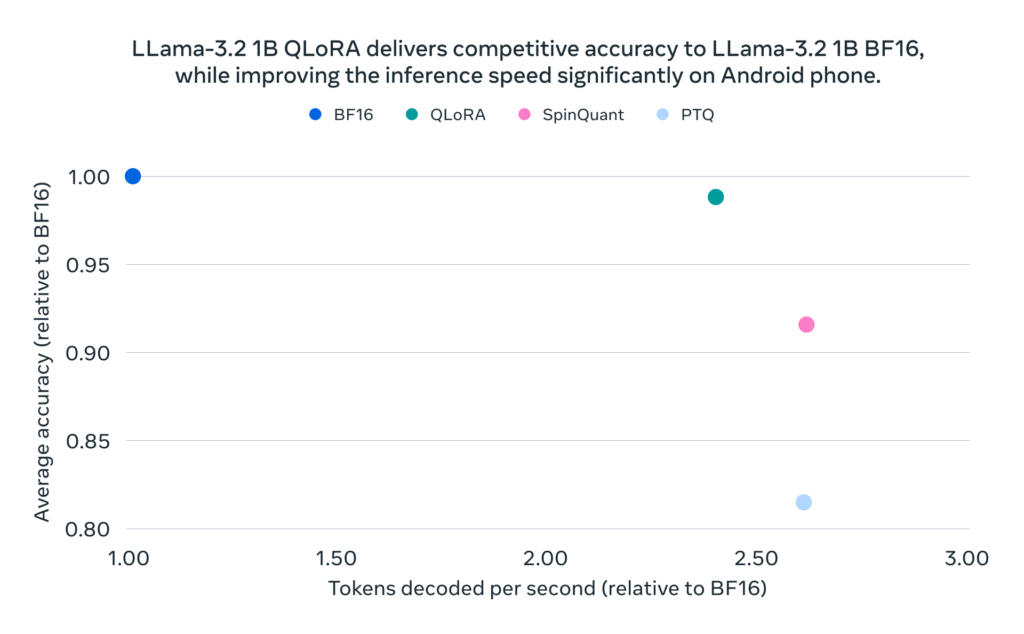
We’re sharing quantized versions of Llama 3.2 1B and 3B models. These models offer a reduced memory footprint, faster on-device inference, accuracy, and performance comparable to their full-precision counterparts
出典:https://ai.meta.com/blog/meta-llama-quantized-lightweight-models/
蒸留技術 大きな教師モデルから小型の生徒モデルに知識を転移する技術で、10倍の高速化を達成しています。 巨大なモデルの知識を効率的に小さなモデルに移すことで、実用的な速度での運用が可能になります。
DistilBERT retains 97% of BERT’s performance while having 40% fewer parameters and being 60% faster. On mobile devices, we see inference speed improvements between 60% to110%.
出典:https://medium.com/huggingface/distilbert-8cf3380435b5
プルーニング技術 ニューラルネットワークの不要な接続を削除することで、30-40%の軽量化を実現しています。 学習済みモデルから重要度の低いパラメータを除去することで、性能を保ちながらサイズを削減できます。
これらの技術により、パラメータ数が増加してもある程度の効率性を保つことができており、最新のモデルでは同じ処理を従来比40%少ないリソースで実行できるようになっているとされています。
推論能力強化の革新的技術
思考の連鎖(Chain-of-Thought)技術 特に注目すべきは「思考の連鎖(Chain-of-Thought)」技術です。 この技術により、複雑な問題を段階的に解決できるようになりました。
従来のGPTが即座に回答を生成していたのに対し、o1シリーズでは時間をかけて深く思考することで、複雑な問題に対応できるようになりました。 表面的な理解から深い推論へと進化し、単純な質問への即答から複雑な問題への対応へとシフトしています。
o1モデル:「考える」AIの登場 OpenAIが新たに公開したo1モデルは、考えるところまで進化していると言われています。 興味深いことに、o1には「GPT」という頭文字が付いていません。 これは、従来のプレトレーニングモデルとは異なる、全く新しいモデルとして再定義されたことを示しているのかもしれません。
o1は数学の証明問題や博士号レベルの問題にも答えられるようになっており、従来の検索の世界での「速さ」から「深さ」へとパラダイムシフトしています。
例えば、複雑な投資戦略について質問すると、o1は75秒ほど時間をかけて深く考えた上で回答を提供します。 時間はかかりますが、その分、より質の高い答えを得られる可能性があります。
AI活用・DXを推進する法人研修
企業様の課題や人材育成計画にあわせた法人研修・DX推進プログラムを企画・提供させていただいています。基礎から応用・開発まで気軽にお問合せください。
ブラックボックス問題への対処法

ブラックボックス問題の本質と課題
| 透明性技術 | 説明可能性 | 適用分野 | 限界 |
|---|---|---|---|
| XAI技術 | 約80% | 画像認識・分類 | 複雑な推論には不十分 |
| 思考の連鎖表示 | 約75% | 論理問題・数学 | 創発的推論の説明困難 |
| 制約付きモデル | 約90% | 金融・医療 | 柔軟性の制限 |
ChatGPTの学習方法で避けて通れない課題が「ブラックボックス問題」です。 これは「AIが出した答えが、どのような過程で導き出されたのか分からない」という問題で、現代のAI技術における最大の課題の一つです。
なぜブラックボックス化するのか 従来のAIは人間がルールを決めて、コンピューターにルールに合致するかどうかを判断させる手法でした。 しかし、ChatGPTのようなディープラーニングでは、コンピューター自身が判断するルールを学習します。
ChatGPTには1.8兆~3.5兆という膨大なパラメータが複雑に相互作用しており、特定の出力を生成した「直接的な理由」を特定することは現在の技術では困難です。 例えば、医療診断で「なぜこの病名を提示したか」の説明が困難な場合があるのは、数多くのパラメータが複雑に絡み合って結論を導いているためです。
透明性向上への具体的取り組み
XAI(説明可能AI)技術 判断根拠の可視化技術により、重要度マップによる入力分析で約80%の説明可能性を達成しています。 画像認識では、どの部分に注目して判断したかを色分けして表示することで、ある程度の説明が可能になっています。
思考の連鎖表示技術 推論過程を段階的に表示することで、約75%の説明可能性を実現しています。 数学問題などでは、解法の手順を明示することで、人間が理解できる形での説明が可能になりました。
制約付きモデル 論理ルールを明示的に組み込む手法で、約90%の説明可能性を達成していますが、主に金融や医療などの限定的な分野での適用となっています。 あらかじめ決められたルールに従って動作するため、説明は容易ですが、柔軟性が制限されるという制約があります。
用途別の使い分け指針と実践的アプローチ
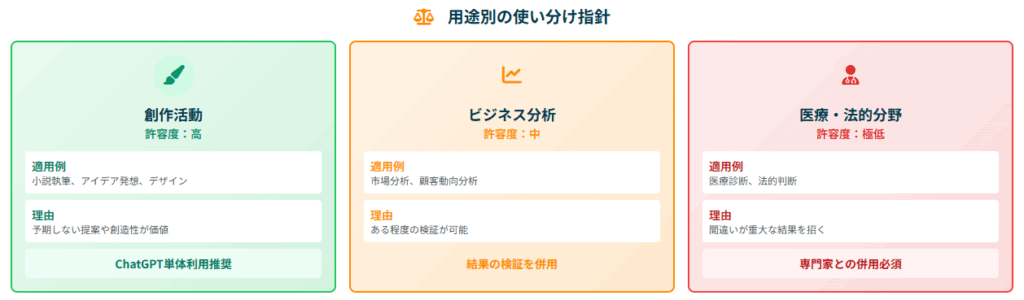
ビジネス分析での活用 ビジネス分析では中程度の許容度で、結果の検証を併用することが望ましいでしょう。 市場分析、顧客動向の分析などでは、ChatGPTの提案を参考にしつつ、人間の専門家による検証を組み合わせることが効果的です。
医療・法的分野での活用 医療診断では許容度が低く、専門家との併用が必須となります。 法的判断では極めて低い許容度のため、補助ツールとしてのみの利用が適切です。 これらの分野では、間違いが重大な結果を招く可能性があるため、AIの判断を最終決定として採用することは避けるべきです。
創作活動での活用 創作活動ではブラックボックスの許容度が高く、ChatGPT単体での利用が推奨されます。 小説執筆、アイデア発想、デザインなどでは、予期しない提案や創造的な発想が価値を持つため、説明可能性よりも創造性が重視されます。
ChatGPTを支える物理インフラの実態
データセンターの規模と地理的分散
OpenAIの戦略的拠点展開 OpenAIは米国テキサス州で1.2ギガワット規模のデータセンターを建設中で、これはStargateプロジェクトの第一弾として位置づけられています。 さらに16州で追加のデータセンター建設を計画しており、アリゾナ、カリフォルニア、フロリダ、オハイオ、オレゴン、ペンシルベニアなどが候補地として挙げられています。
特に注目すべきは、アブダビで計画されている5ギガワット規模の施設で、これはモナコより広い面積を必要とする巨大なプロジェクトです。 この規模の施設は、原子力発電所5基分に相当する電力を消費することになります。
Googleの分散戦略 Googleは世界16拠点に分散配置し、北米ではアイオワ、オレゴン、ネバダ、欧州ではベルギー、フィンランド、アジア太平洋ではシンガポール、東京、大阪などに拠点を構えています。 最大2GWの電力消費でクラウド統合を図っており、地理的リスクの分散と各地域のデータ保護規制への対応を重視しています。
環境負荷と持続可能性への取り組み
大規模なAI学習は膨大な電力を消費するため、環境負荷が大きな課題となっています。 ChatGPTの学習と運用によるCO2排出量は、中型都市1つ分に相当するとされており、環境への影響が懸念されています。
OpenAIやGoogleなどの企業は、再生可能エネルギーの活用や冷却効率の改善に取り組んでいます。 フィンランドのデータセンターでは海水冷却を採用し、テキサスの新施設では「低水使用設計」を検討するなど、環境負荷軽減のための技術開発が進められています。
しかし、AI技術の急速な発展とパラメータ数の増加により、エネルギー消費量は今後も増加する見込みで、根本的な解決には時間がかかりそうです。
学習期間と継続的改善の仕組み
学習データの更新サイクルと改善プロセス
ChatGPTの学習は一度きりではなく、継続的に行われています。 基礎学習データは年1-2回の頻度で完全再学習が行われ、モデル全体に影響を与えます。 この大規模な再学習には数ヶ月から1年程度の期間が必要で、膨大なコストと時間がかかります。
専門知識については四半期毎にファインチューニングが実施され、特定分野の精度向上が図られます。 医療、法律、金融などの専門分野では、最新の研究成果や法改正などを反映するため、より頻繁な更新が行われることもあります。
リアルタイム情報については、RAG(検索拡張生成)技術を活用して日次で更新され、最新情報を反映できる仕組みが構築されています。 この技術により、学習データの限界を超えて、最新のニュースや情報にも対応できるようになっています。
フィードバックループの詳細メカニズム
ChatGPTの継続的改善は、以下の詳細なサイクルで実現されています。
データ収集フェーズ(1-2ヶ月)
ユーザーとの会話ログ、専門家からの評価、エラー報告などを収集し、分析します。 どのような質問で間違いが多いか、どの分野での精度が不足しているかなどを特定し、改善点リストを作成します。
データキュレーションと品質管理
収集したフィードバックデータを整理し、ノイズやバイアスを除去します。 高品質なデータのみを再学習に利用することで、モデルの精度低下を防ぎます。
モデル調整フェーズ(2-3ヶ月)
特定された問題点に対して、パラメータを再学習し、更新モデルを生成します。 この段階では、大量のGPUリソースを使用して集中的な学習が行われます。
テスト評価フェーズ(1ヶ月)
更新されたモデルの性能を様々な観点から検証し、品質レポートを作成します。 安全性、精度、倫理性などの多面的な評価が行われます。
デプロイフェーズ(1週間)
テストに合格したモデルを段階的に本番環境に適用し、新バージョンとして提供開始します。 ユーザーへの影響を最小限に抑えるため、段階的なロールアウトが行われます。
AI活用・DXを推進する法人研修
企業様の課題や人材育成計画にあわせた法人研修・DX推進プログラムを企画・提供させていただいています。基礎から応用・開発まで気軽にお問合せください。
まとめ:ChatGPT学習の仕組みを活用するために
ChatGPTの学習メカニズムを理解することで、その能力を最大限に活用できるようになります。 パラメータ数の増加により精度は着実に向上していますが、ブラックボックス問題や膨大な運用コストという課題も存在しています。
企業利用では学習無効設定を選択して機密情報の漏洩リスクを軽減し、創作活動では通常設定で創造性向上を図ることが効果的です。 学習支援では通常設定を使いつつ情報の検証を怠らず、専門業務ではブラックボックス問題に対応して結果の検証を必須とすることが重要です。
AI技術は「検索の時代」から「理解の時代」、そして「考える時代」へと急速に進化しています。 o1モデルに代表される「考えるAI」の登場により、従来不可能だった複雑な問題解決や創造的な作業にもAIが活用できるようになりました。
これは「知のゴールドラッシュ」とも呼ばれる現象で、AIを効果的に活用できる人や組織が競争優位を築ける時代になっています。 調べるだけなら知っている人ばかりの世の中では競争に勝てませんが、人が知らないことを先に考えさせて、先に問題を解決するから競争に勝てるのです。
ChatGPTの学習方法を理解し、その特性を踏まえて用途に応じた適切な設定と使い方を心がけることで、AI技術の恩恵を最大限に受けることができるでしょう。 今後もさらなる発展が期待されるAI技術ですが、基本的な仕組みを理解しておくことが、効果的な活用の第一歩となるはずです。



